Network Optimization modeling
You can use input tables to define specific conditions in your supply chain. These include:
- Time periods
- Network flows
- Transportation modes and multi-stop estimated costing
- Process modeling
- Financial modeling and taxes and duties
- Spatial modeling
- Demand timing
Using grouped and individual records
As you populate input tables, it is wise to be aware of the precedence used in the case of duplicate records. Duplicate records can occur when you define multiple records with groups or when you have both individual and grouped records. When the model is run and input files are generated, duplicate records are not written to the input files. The selection of records is based on group vs. individual records, along with the order of records in the model input table. The logic is basically as follows:
- Individual records (with exact matches) are written first based on the highest record ID number. The highest record ID is in the record most recently added to the table.
- Once all individual exact matching records are written, records with a single group are expanded and populate any missing record based on the highest record ID number.
- Next, records with two groups are expanded and populate any missing record based on the highest record ID number.
and so on, until all allowed individual records have been written based on the input table.
For example, assume the following Transportation Policies:
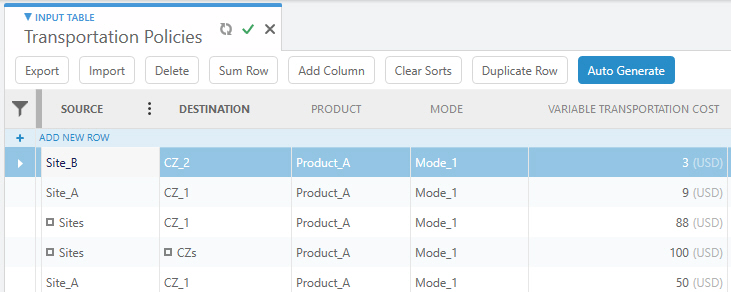
When the model is run, the input file contains the following values:
| Source | Destination | Product | Mode | Variable Transportation Cost | Notes |
|---|---|---|---|---|---|
| Site_A | CZ_1 | Product_A | Mode_1 | 50 | Exact match with highest ID (of the two exact match records) |
| Site_A | CZ_2 | Product_A | Mode_1 | 100 | From record with multiple groups |
| Site_B | CZ_1 | Product_A | Mode_1 | 88 | From record with single group |
| Site_B | CZ_2 | Product_A | Mode_1 | 3 | Exact match |
Last modified: Wednesday May 15, 2024